Sorbet Compiler: An experimental, ahead-of-time compiler for Ruby
For the past year, the Sorbet team has been working on an experimental, ahead-of-time compiler for Ruby, powered by Sorbet and LLVM. Today we’re sharing the source code for it. It lives alongside the existing code for Sorbet on GitHub, mostly in the compiler/ folder:
→ https://github.com/sorbet/sorbet/tree/master/compiler/
We want to be clear up front: the code is nowhere near ready for external use right now, but we welcome you to read the code and give us feedback on our approach!
We teased this a few weeks back in a tweet, which drew a fair bit of attention, and also a lot of questions:
We're big believers in multi-year infrastructure bets. After a few years of Ruby infra work, our in-house Ruby compiler is now 22–170% faster than Ruby's default implementation for Stripe's production API traffic. If interested in working on such problems, we're hiring!
— Patrick Collison (@patrickc) June 30, 2021
Before answering the questions raised in the above discussion, some disclaimers:
If you’re an existing Sorbet user, nothing changes for you! You can continue to use Sorbet to typecheck your Ruby codebases exactly as you do now. While the Sorbet Compiler code lives in the Sorbet repo, it doesn’t change anything about Sorbet, nor is it required to use Sorbet.
There are no Sorbet Compiler binary releases. If it works out, we may some day publish pre-built binaries of the Sorbet Compiler, but right now we don’t have any firm plans. We welcome you to read the source and try to compile it yourself if you’re curious.
While we are using the Sorbet Compiler at Stripe in production, it should NOT be considered “production ready.” We won’t prioritize fixing issues that don’t also affect Stripe. It is an internal experiment developed in the open.
With those disclaimers out of the way, let’s dive into the frequently asked questions.
What’s your goal in open sourcing it now?
We have a few goals. The first handful are entirely pragmatic:
- Even though the Sorbet Compiler’s repo was private, we had already shared it with a handful of companies and individuals, which was toilsome.
- Sometimes improving the compiler requires improving Sorbet. Such changes will only require one PR in one repo now.
- The Sorbet Compiler depends on Sorbet’s internal data structures. Now that the two repos are one, they can share internal data structures directly.
- Much of the Bazel build and test infrastructure in the two repos was duplicated, but can now be shared.
Apart from these pragmatic considerations, we’re interested in gathering feedback from the larger community on our approach. Feel free to read the source code and reach out to us with what you have to say.
Why does Stripe care about Ruby performance?
At Stripe, our primary product is an API. In an API, latency is a feature just as much as what the API lets you do. Stripe is a users-first company, and those users have asked for lower latency.
Improving latency involves doing one of two things:
- Spending less time doing IO (e.g. network and storage), or
- Spending less time in compute (i.e., Ruby)
Other teams at Stripe are tackling latency from the IO angle. In parallel, we’ve been working on building a "big hammer" for improving Ruby compute performance.
Why build a compiler…?
This is our most popular question, and it comes in a bunch of different forms:
- Why build an ahead-of-time compiler, instead of a JIT compiler?
- Why build a compiler, instead of using TruffleRuby or JRuby?
- Why build a compiler, instead of making improvements to the Ruby VM?
- Why build a compiler for Ruby, instead of using another language?
You really want to know why, so here it is!
Why build an ahead-of-time compiler, instead of a JIT compiler?
There are a handful of reasons, which we’ll address one by one.
First, instead of having to ship an entire language runtime to production, with an ahead-of-time compiler the compilation happens once in CI. We already ship various generated code and data files in our deploy archives—compiled artifacts fit seamlessly with our existing build pipelines. This also limits the blast radius if something were to go wrong: if we need to “turn off” the compiler, we just stop loading the compiled archives and let the Ruby VM run the original source.
Another point: ahead-of-time compilers are conceptually simpler. When we kicked off the Sorbet Compiler project, we estimated that it would take us less time to build an ahead-of-time compiler delivering real-world performance improvements than it would take to build a JIT that fulfills both our latency goals and Stripe security requirements. As we’ll discuss below, our chosen implementation strategy makes ahead-of-time compilation simpler and easier to roll out gradually.
And finally, ahead-of-time compilation lets the project exploit type information present statically, after Sorbet has type checked a project. While a JIT observes the types at runtime to inform how it compiles the code, Sorbet already has this information present (unless the code uses T.untyped). Of course, this is a classic tradeoff between a compiler and a JIT: sometimes the runtime type information is actually better, because JITs can see through interfaces and polymorphism. We don’t claim to have solved this tradeoff in the Sorbet Compiler, but Stripe’s Ruby codebase is extensively covered by Sorbet, and is thus uniquely positioned to make use of this static type information.
Why build a compiler, instead of using JRuby or TruffleRuby?
Many people in the Ruby community have found success replacing the Ruby VM with either JRuby or TruffleRuby. JRuby makes it easy for Ruby to interoperate with other JVM languages, and the same goes for TruffleRuby with GraalVM. Both claim impressive performance improvements as well as enticing features like multicore, shared-memory concurrency.
But nearly all of Stripe’s codebase is implemented in Ruby running on the default Ruby VM (YARV). Not only did we not need Java VM-level interoperability, choosing either alternative Ruby implementation would have made for a difficult migration path. Stripe relies heavily on gems with native extensions, and as you can imagine, a multi-million line Ruby codebase over time starts to depend on Ruby-the-implementation, not just Ruby-the-language.
Another hurdle in switching to one of these implementations is that it has to be done at a service boundary. We could have migrated some of Stripe’s smaller services, but Stripe’s most latency-sensitive services are large, monolithic Ruby services without clear breaking points. To adopt JRuby or TruffleRuby in Stripe’s most important services, we’d have to be able to run all the code or none of the code (at least on a subset of traffic).
Below we’ll talk below the implementation of the Sorbet Compiler, which solves for this situation in a couple of ways:
The Sorbet compiler targets Ruby native extensions, which trivially interoperate with all other Ruby code. We don’t have to give up the Ruby VM (quirks and all), and can continue to use all our existing gems and native extensions.
Because it compiles to native extensions, we can enable the compiler at the source file level instead of the service level. While we iron out the bugs in our compiler and adopt it in production, we can carve out arbitrarily large or small swaths of Stripe’s codebase to experiment with.
Why build a compiler, instead of making improvements to the Ruby VM?
Another way of phrasing this question: are you going to upstream your changes to the Ruby VM?
Ruby is fundamentally an interpreted language. Apart from maybe having a CI step to pre-download third-party gems, many Ruby projects do not have any sort of build step—the project’s Ruby source code is meant to run unprocessed by the Ruby VM.
By contrast, our hypothesis was that we could deliver substantial performance improvements by paying the cost of a one-time compilation step. Stripe already has an extensive Ruby build pipeline, so this cost is minor.
And as mentioned above, the Sorbet Compiler relies entirely on Sorbet. Specifically: it cannot work in a project that has not already adopted Sorbet. The Ruby maintainers have made it very clear that they do not want to force static typing on all users of the language, so there’s no place for the Sorbet Compiler upstream.
Why build a compiler for Ruby, instead of using another language?
Great question, and the answer is: at Stripe we’re doing both!
A handful of teams at Stripe urgently need their code to run faster. Maybe a team’s highest priority is improving latency in a small service with clear boundaries. Or maybe a team is starting a greenfield project and anticipates performance bottlenecks. Teams at Stripe have the choice between Ruby, Java, and Go to build services in, depending on their needs.
But Stripe’s existing Ruby codebase is many millions of lines, and implements Stripe’s most business-critical workloads. Even if we wanted to get rid of Ruby (remember: many people value the unique expressiveness of Ruby!), it would take a long time to rewrite all of Stripe’s Ruby code into another language.
As teams rewrite or build smaller projects in other languages, our team has been working to tackle the elephant in the room: the millions of lines of existing Ruby code powering Stripe’s core products.
How does it work?
The Sorbet Compiler is an ahead-of-time compiler for Ruby codebases that use Sorbet, powered by LLVM and the existing Ruby VM. The high level technique looks like this:
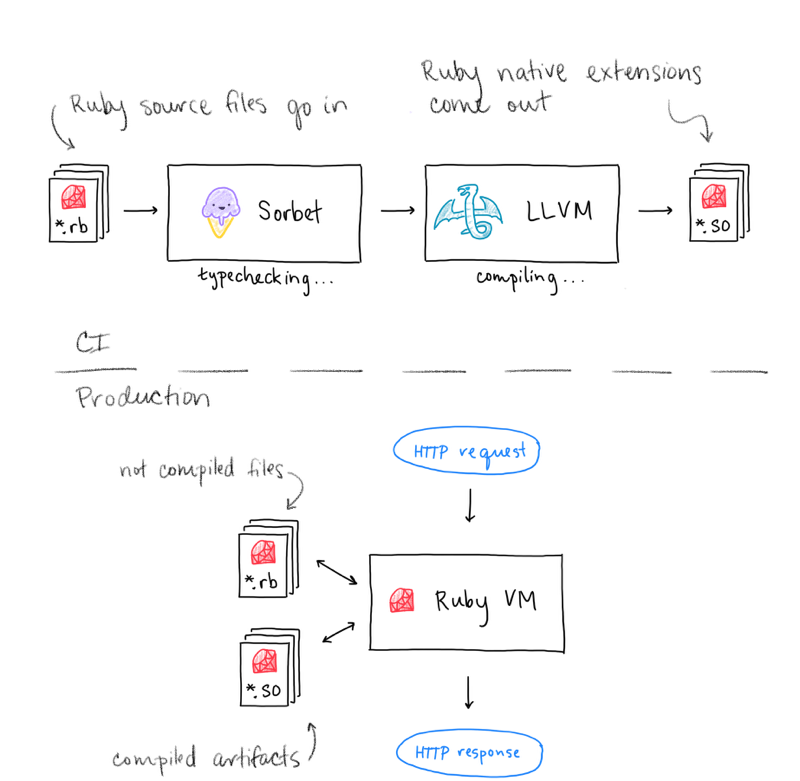
There are two phases: what happens in CI (to compile the code), and what happens in production (to run the code).
When compiling the code, we start with normal *.rb source files, feeding them to Sorbet to be typechecked. The output of type checking is a custom type-annotated intermediate representation (IR), which the Sorbet Compiler consumes to generate LLVM IR. LLVM takes this IR and generates native shared object (*.so) files.
These shared objects are actually valid Ruby native extensions, conforming to and using the same APIs as gems which include native extensions use. Thus, the compiled artifacts use the same object model and runtime representation that all other Ruby code uses!
The Ruby VM exposes quite an extensive set of APIs to extension authors, which are sufficient to call back into the Ruby VM when a faster compilation strategy doesn’t exist for a particular language feature. We might write more in the future about how specifically we go from Sorbet’s typed IR to Ruby native extensions, but this means that there is very little the Sorbet Compiler can’t handle.
The decision to compile or not compile a file is made by adding a # compiled: true or # compiled: false comment to the top of a Ruby source file. If a file is compiled, the compiled artifact is bundled into a service’s deploy archive like all other Ruby and data files.
At runtime, a small support module monkeypatches require_relative to skip requiring the original *.rb file and instead require the newly compiled *.so file if possible. Since these compiled artifacts are Ruby native extensions, they can define classes, modules, and methods just the same as if a Ruby file had been required.
Architected this way, the Sorbet Compiler turns Ruby into a language for writing Ruby native extensions! Instead of having to write C, C++, Rust, or some other compiled language to write native extensions, people can continue to write Ruby but gain the benefits of native compiled speeds.
How fast is it?
We’re still very early on in the project, but we’re encouraged by our initial results. We’ve been running the Sorbet Compiler in production at Stripe for about a year, and as the tweet above mentioned, we’re finally starting to see the payoff, with varying results depending on the workload.
That being said, we don’t have much more to share about performance right now. We measure ourselves not against synthetic benchmarks, but against real-world Stripe workloads, which are not public. We have some synthetic benchmarks checked into the source repository, but none of these are representative and mostly serve to help us debug and minimize performance problems we’ve seen in the wild.
If you have a production workload you’d like to try the Sorbet Compiler on feel free to take the source code and get it running your benchmark (of course: a pre-requisite will be getting the benchmark to typecheck with Sorbet). Expect hiccups and maybe even show-stopping bugs, as we have not tested the compiler in environments that differ from Stripe’s internal production environment. If you do try things out, feel free to let us know!
What’s next?
Over the next six months we’re going to be heads down focusing on making the Sorbet Compiler perform even better on real-world code at Stripe. We’re excited to share more with you once we’ve made more progress!
To get in touch with us, find us on our Sorbet Slack:
Thanks!
— The Sorbet team